环境
python3.8(anaconda)
pandas,numpy,scipy,statsmodels
统计习题
www.docin.com/p-1031244688.html
http://www.docin.com/p-646075818.html
https://wenku.baidu.com/view/fa4a7f1cccbff121dc368320.html
https://wenku.baidu.com/view/836785c8360cba1aa811da31.html
苏大医学统计题库
https://wenku.baidu.com/view/e8049c92f68a6529647d27284b73f242326c31c8.html
题库:https://wenku.baidu.com/view/df65904f17fc700abb68a98271fe910ef12daefc.html
常见分布
正态分布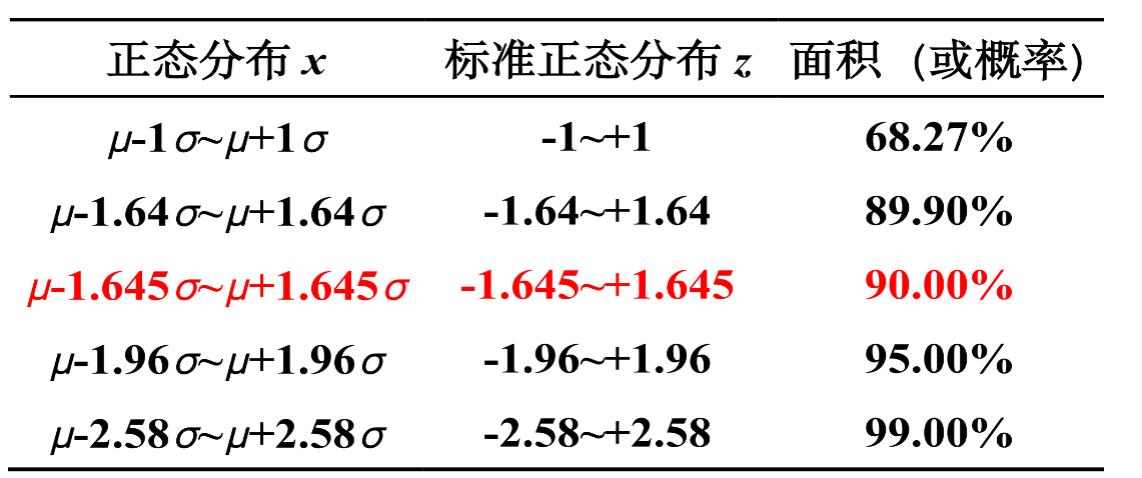
用(约包含95%的个体观察值) 作为上、下警戒值;以( 约包含99.73%的个体观察值)作为上、下控制值。
先计算Z值,看Z值范围。
二项分布
t分布
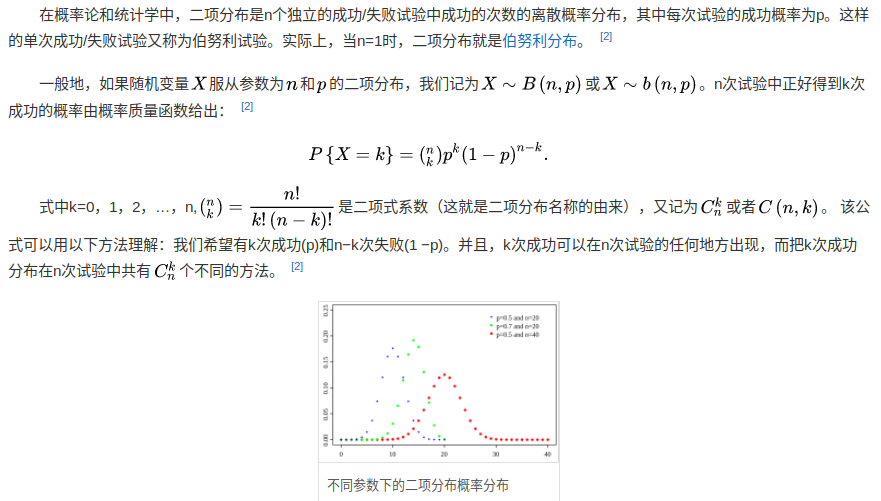


1,两个二项分布的和为二项分布
2,伯努利分布是二项分布在n= 1时的特殊情况。X~ B(1,p)与X~ Bern(p)的意思是相同的。相反,任何二项分布B(n,p)都是n次独立伯努利试验的和,每次试验成功的概率为p。
3,当试验的次数趋于无穷大,而乘积np固定时,二项分布收敛于泊松分布。因此参数为λ=np的泊松分布可以作为二项分布B(n,p)的近似,近似成立的前提要求n足够大,而p足够小,np不是很小。
4,如果n足够大,那么分布的偏度就比较小。在这种情况下,如果使用适当的连续性校正,那么B(n,p)的一个很好的近似是正态分布:

超几何分布:拿出不放回
#假设检验
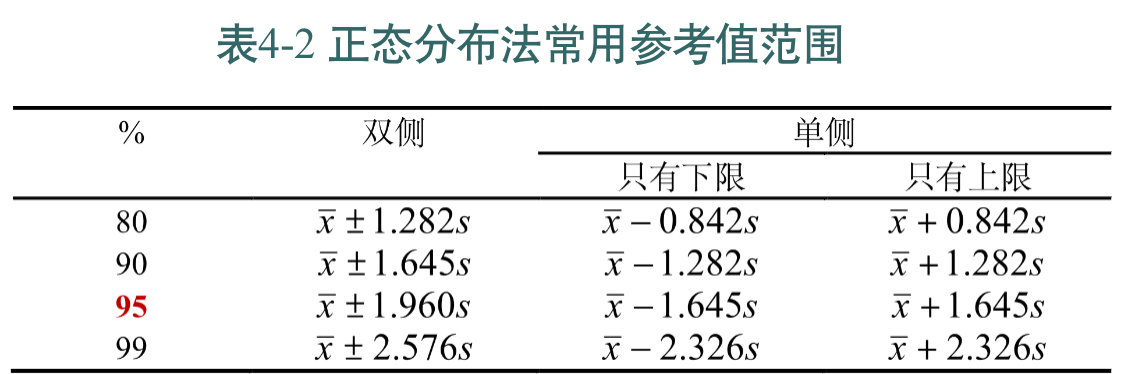
检验数据为正态分布
H0:样本来自正态分布的总体
H1:样本不是来自正态分布的总体
- W检验 shapiro(当模型数量在(3,50)之间的时候)
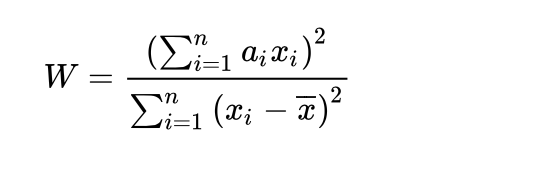
1.对于数据排序,使X1<X2<X3…
2.查表得到a的值。
1 | >>> from scipy import stats |
shapiro_test这个元组第一个为w值第二个为p值。
- D检验 KS检验(当模型数量在(50,1000)的时候)
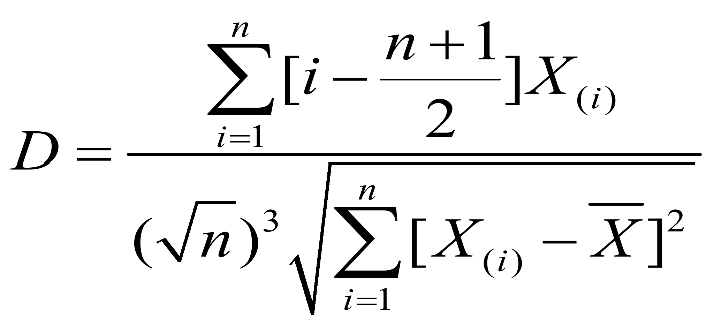
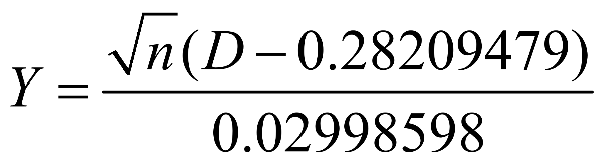
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15scipy.stats.kstest(rvs, cdf, args=(), N=20, alternative='two-sided', mode='auto')
alternative:双边或者单边。{‘two-sided’, ‘less’, ‘greater’},
rvs, cdf:数组或者可以生成随机数组的函数或者字符串(scipy指定的分布)
N:样本的大小。
mode:计算p值得分布的方法。默认auto。
‘auto’ : selects one of the other options.
‘exact’ : uses the exact distribution of test statistic.
‘approx’ : approximates the two-sided probability with twice the one-sided probability
‘asymp’: uses asymptotic distribution of test statistic
return D,p
(有时候的样本标准化之后还是通不过shapiro和ks检验,这时候就把他当偏态处理。比方说两样本的差异不能用ttest而要用秩和检验)
(数据右偏的话可以对所有数据取对数、取平方根等,它的原理是因为这样的变换的导数是逐渐减小的,也就是说它的增速逐渐减缓,所以就可以把大的数据向左移,使数据接近正态分布。
如果左偏的话可以取相反数转化为右偏的情况。待考证)
- t检验
t检验分为单样本t检验,独立样本t检验和配对样本t检验。
单样本和独立样本是比较均值的就是顺序无所谓,配对必须1对1检验。
配对样本计算公式https://www.jmp.com/en_ch/statistics-knowledge-portal/t-test/paired-t-test.html
p值越大,t值越小。
注意:
1,最低抑制浓度(mg/L)为倍数关系,计算平均数应该使用几何平均数。
1 | from statistics import mean |
- 方差齐次性检验
两组数据大的方差除小的方差为F值。1
2
3scipy.stats.levene(*args, **kwds)
Returns (statisticfloat:The test statistic.,pvaluefloat:The p-value for the test)
stat, p = levene(a, b, c) - Z检验
- t’检验
Welch’s t 检验,scipy.stats.ttest_ind(equal_var=False)
方差不齐时,但是两组数符合正态分布 - 方差分析(ANOVA)
如果用均方(离差平方和除以自由度)代替离差平方和以消除各组样本数不同的影响,则方差分析就是用组间均方去除组内均方的商(即F值)与1相比较,若F值接近1,则说明各组均值间的差异没有统计学意义,若F值远大于1,则说明各组均值间的差异有统计学意义。
当计算的F值超过F(r-1,n-r)(在0.05置信范围下),拒绝原假设。
使用条件1,样本都来自正态分布。2,通过方差齐次性检验。
如果来自正态分布但是不符合方差齐次性检验:矫正p值
如果样本不符合正态分布,用非参秩和检验
- Mann-Whitney U检验
stats.mannwhitneyu([1,2,3,54,6,7],[8,4,5,6,3,5,6,433,5,6])#n>20独立样本检验,两组数长度不一样
stats.ranksums([1,2,3,54,6,7],[8,4,5,6,3,5,6,433,5,6])#n<20独立样本检验,两组数长度不一样
stats.wilcoxon([1,2,3,54,6,7],[8,4,5,6,3,5])#两组数长度一致
统计量
1, MAD(Median absolute deviation, 中位数绝对偏差)是单变量数据集中样本差异性的稳健度量。mad是一个健壮的统计量,对于数据集中异常值的处理比标准差更具有弹性,可以大大减少异常值对于数据集的影响。
对于单变量集X={X1,X2,X3,…,Xn}X={X1,X2,X3,…,Xn},MAD的计算公式为:
MAD(X)=median(|Xi−median(X)|)
2,FDR(false discovery rate),是统计学中常见的一个名词,翻译为伪发现率,其意义为是 错误拒绝(拒绝真的(原)假设)的个数占所有被拒绝的原假设个数的比例的期望值。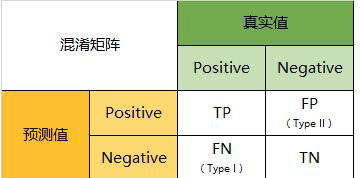


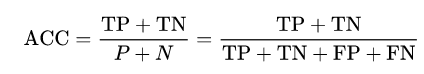
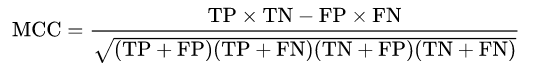
3,皮尔逊相关系数。
协方差除两个变量的离差平方和
当两个变量的标准差都不为零时,相关系数才有定义,皮尔逊相关系数适用于:
1). 两个变量之间是线性关系,都是连续数据。
2). 两个变量的总体是正态分布,或接近正态的单峰分布。(满足双变量正态分布)。
3). 两个变量的观测值是成对的,每对观测值之间相互独立。
Kendall’s tau相关系数:
对于双向有序资料。
针对一个双向有序表,可以将X和Y列成n个数据对(xi,yi),这一点很容易理解,相关系数计算的条件必须是成对数据。如果X和Y正相关,那么两个变量必然有相同的变化,要变大都变大,也变小也都变小,如 (1,2) ~ (2,4)、(5,3) ~ (2,2)等,这样变化的对叫做协和对(concordant pair);如果是负相关,则两个变量的变化是相反的,如(1,2) ~ (2,1)、(5,3) ~ (2,4),则称为不协和对(disconcordant pair);如果出现这样的对,如(1,2) ~ (1,3)、(5,3) ~ (3,3)、(1,1) ~ (2,2),即在变化中至少有一个变量没发生变化,则既不是协和对也不是不协和对,我将其简称为 “不变对”。
如果协和对显著多于不协和对,则为正相关;反正则为负相关;如果两种对中没有明显多的对,则说明两个变量不存在相关关系。
1 | scipy.stats.kendalltau(x, y, initial_lexsort=None, nan_policy='propagate', method='auto') |
Spearman秩相关系数:利用两变量的秩次大小作线性相关分析,统计效能比Pearson相关系数要低一些。
把皮尔逊相关系数的数值换为秩。
1 | scipy.stats.spearmanr(a, b=None, axis=0, nan_policy='propagate')[source] |
双全中值相关: biweight midcorrelation efficiently
med 中位数.
mad(median absolute deviation):中值绝对偏差
1 | statsmodels.robust.scale.mad(a, c=0.6744897501960817, axis=0, center=<function median>) |
ref:Gene differential coexpression analysis based on biweight correlation and maximum clique
3,离差平方和
离差平方和(Sum of Squares of Deviations)是各项与平均项之差的平方的总和。定义是设x是一个随机变量,令η=x-Ex, 则 称 η为x的离差,它反映了x与其数学期望Ex的偏离程度。
标准误,即样本均数的标准差,是描述均数抽样分布的离散程度及衡量均数抽样误差大小的尺度,反映的是样本均数之间的变异。标准误不是标准差,是多个样本平均数的标准差。
常见的问题
1,训练模型中,features同时出现连续性变量和离散型变量。
对于方差分析可以采用协方差分析,对于svm等可以采用信息熵。
对于决策树和随机森林不需要考虑
第三章 数值变量资料
绝对数:在医学研究中清点分类资料得到的数据被称为绝对数。
相对数:医学研究中常用于描述分类资料的相对数包括率、构成比及相对比等统计指标,这些指标都是由两个有联系的指标之比组成,故称之为相对数(relative number)。
常用相对数:率,构成比,相对比(两个有关的指标A、B之比)
注意:
1,计算相对比时,分母不要太小。
2,样本率或构成比的比较不要直接比较,应作假设检验比较。
标准化
标准化法(standardization method)就是在一个指定的标准构成条件下进行率的对比的方法。
基本思想是将所比较的两组或多组资料,按照选定的某个统一标准构成计算得到理论的或预期的率,再作比较。经过标准化处理得到的率被称为标准化率(standardized rate)或调整率(adjusted rate)。
- 直接标准化:已知率,将数据总数统一为标准组,算出预期数,算出比率。
已知被标化组的各层阳性事件率时,宜采用直接法计算标准化率。
(1)已知标准组年龄别人口数时,标准化率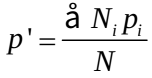
- 间接标准化法
当被标化组的各层事件阳性数或阳性率未知,可采用间接标准化法。间接标准化法必须有标准组的各层事件阳性率,计算公式为: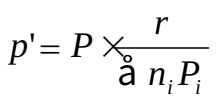
(2)已知标准组年龄别人口构成比时,标准化率 的计算公式为:
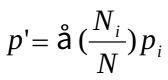
平均发展速度=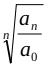
平均增长速度=平均发展速度-1
定基发展速度,即各时期指标与基期指标之比。
定基比发展速度=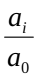
定基比增长速度=定基比发展速度-1
各时期或时点的指标数值各相当于前一个时期指标数值的倍数,称为环比发展速度。
环比发展速度=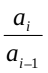
环比增长速度=环比发展速度-1
正态分布


皮尔逊相关系数和协方差的关系:
如何理解皮尔逊相关系数(Pearson Correlation Coefficient)? - TimXP的回答 - 知乎
https://www.zhihu.com/question/19734616/answer/117730676



t’ 检验:
https://www.cnblogs.com/abble/p/11191467.html
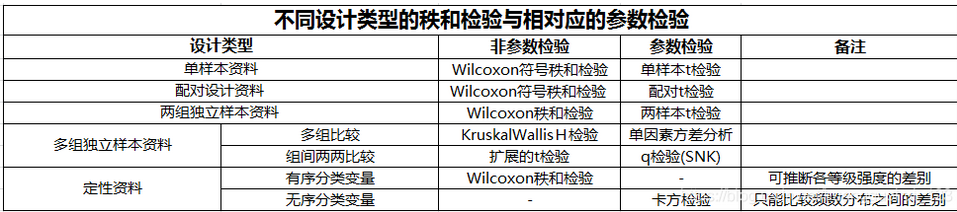
M检验 cmh2检验 q检验
对不同情况计算止此,配对的…..

wenyuhao
生物信息学